Low Light Metrics
Content
本文记录了LPIPS、SSIM、MAE、MSE、PSNR、NIQE和NIMA共计七个低照度指标,除了介绍相关背景、意义,也会提及算法实现的大致过程。
LPIPS
全称:Learned Perceptual Image Patch Similarity,中文:学习感知图像块相似度,又称感知损失
是用于度量两张图像差别的一种指标,最开始由论文《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》提出。
给定Ground Truth图像参照块x和含噪声图像失真块x0,由论文可知这两个块都是图像输入到AlexNet得到的。
感知相似度度量公式如下:
d(x,x0)=l∑HlWl1h,w∑∣∣wl⊙(y^hwl−y^0hwl)∣∣22
其中,d为x0与x之间的距离。从L层提取特征堆(feature stack)并在通道维度中进行单位规格化(unit-normalize)。利用向量wl来放缩激活通道数并计算L2距离。最后在空间上平均,在通道上求和。
网络结构如下:
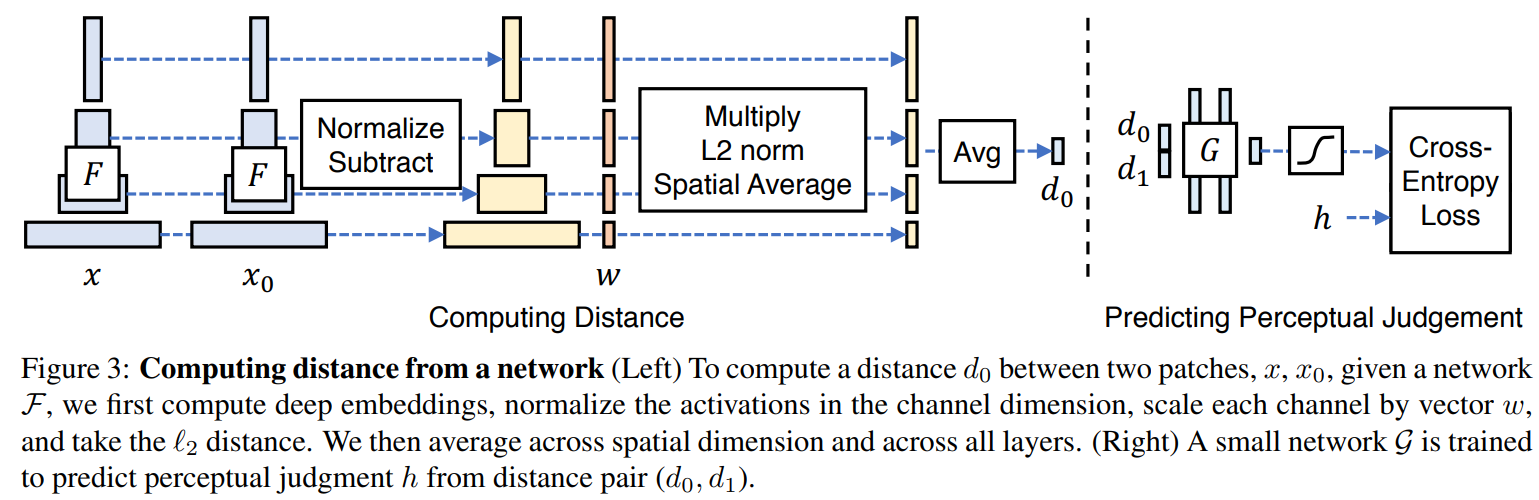
基于学习的相似度得分损失函数公式如下:
L(x,x0,x1,h)=−hlogG[d(x,x0),d(x,x1)]−(1−h)log{1−G[d(x,x0),d(x,x1)]}
给定Ground Truth图像参照块x和含噪声图像失真块x0的距离d0、Ground Truth图像参照块x和含噪声图像失真块x1的距离d1,这两个距离均由AlexNet计算得出,在顶部训练一个网络G(包含2个32通道FC-ReLU层、1通道FC层和sigmoid层)映射到得分h。这个得分也就是我们所求。
依照个人理解这里的h其实就是G[d(x,x0),d(x,x1)],而L则代表信息熵「信息熵其实从某种意义上反映了信息量存储下来需要多少存储空间」,由于事件空间只有两种状态,对应的概率为{p,1−p}。当该信息熵缩小时,不确定性也在逐渐减小,这意味着这两个概率的结果趋于一致,信息量存储所要的空间也趋向于最小「这也是我们所求的最优策略」。再看p(x)和p′(x)分别表示G[d(x,x0),d(x,x1)]和1−G[d(x,x0),d(x,x1)],推敲一下不难发现他们代表的意义是x0,x1的特征差距大小所映射的概率。
SSIM
全称:Structural Similarity Index,中文:结构相似性指数
**是一种用于量化两幅图像间的结构相似性的指标。**它仿照了人类视觉系统实现了结构相似性的有关理论,对局部结构变化的感知敏感。SSIM分别用均值来估计亮度,用方差来估计对比度,用协方差来估计结构相似程度。它的值域是[0,1],而且当SSIM=1时,两张图片完全一致。
给定两张图片A和B,两者之间的照明度(luminance)、对比度 (contrast) 和结构 (structure)分别如下公式所示:
l(x,y)c(x,y)s(x,y)=μx2+μy2+c12μxμy+c1=σx2+σy2+c22σxσy+c2=σxσy+c3σxy+c3
一般地,有:
- c3=2c2
- μx为x的均值
- μy为y的均值
- σx2为x的方差
- σy2为y的方差
- σxy为x与y的协方差
- c1=(k1L)2,c2=(k2L)2为两个常数,是为了避免0作为除数的情况
- L为像素值的范围,即2B−1
- k1=0.01,k2=0.03为默认值
而SSIM被定义为:
SSIM(x,y)=[l(x,y)α⋅c(x,y)β⋅s(x,y)γ]
令α=β=γ=1,则有:
SSIM(x,y)=(μx2+μy2+c1)(σx2+σy2+c2)(2μxμy+c1)(2σxy+c2)
MAE
用于计算平均绝对误差,用来衡量两图片之间的差距,但由于绝对值符号的存在,求得的导数并不平滑,有些点导数不存在,因此不适合作为Loss,但它能很好地衡量差距。
对于给定的两个图片x和y,其计算公式如下:
MAE(x,y)=W×H1i=0∑W−1j=0∑H−1∣x(i,j)−y(i,j)∣
MSE
用于计算平均平方误差,用来衡量两图片之间的差距,平方的特性能很好地解决MAE导数不平滑问题,因此它既可以用作Loss的指导参考,又可以衡量差距。
对于给定的两个图片x和y,其计算公式如下:
MSE(x,y)=W×H1i=0∑W−1j=0∑H−1[x(i,j)−y(i,j)]2
PSNR
全称:Peak Signal to Noise Ratio,中文:峰值信噪比
是一种评价图像质量的度量标准,但只是衡量最大值信号和背景噪音之间的图像质量参考值,具有局限性。PSNR的单位为dB,值越大对应图像的失真越少。
给定一个大小为W×H的灰度图I和噪声图K来说,PSNR的定义为:
PSNR=10log10(MSEMAXI2)
其中MAXI为图像中最大像素值,即B-bit的图像的MAXI2值为2B−1。一般地,针对 uint8 数据,最大像素值为255,;针对浮点型数据,最大像素值为1。
有三种方法来计算彩色RGB图像的PSNR:
- 分别计算 RGB 三个通道的 PSNR,然后取平均值;
- 计算RGB各个通道的均方差的均值,然后统一求PSNR;
- 把RGB转化为 YCbCr,然后只计算 Y(亮度)分量的PSNR。
NIQE
全称:Naturalness Image Quality Evaluator,中文:自然图像质量评估
NIQE是ECCV 2018年PIRM比赛时的评价指标,是一种新的无参考图像质量指标。其原理与BRUSQUE一致,因为两者皆出自同一人之手。
前面36个特征提取方法几乎一模一样,但NIQE在提取图像统计特征时先对图像提取了感兴趣区域,这一点源自于人眼更倾向于以图像中更清晰的部分来判断图像质量。所以作者通过计算图像中不同patch的方差场来判别清晰度,选择大于一定阈值的清晰度为自然图像的patch,而失真图像采用全局计算NSS。
NIQE的建模过程比较复杂,分五大部分:
一、Spatial Domain NSS 提取图像空间域特征
首先将图片进行归一化处理,得到MSCN系数:
I^(i,j)=σ(i,j)+1I(i,j)−μ(i.j)
该式表示高斯滤波后求局部均值和局部标准差,其中,
局部均值是对原始图像做高斯模糊处理,具体公式为:
μ(i.j)=k=−K∑Kl=−L∑Lwk,lI(i+k,j+l)
局部标准差是对原始图像和局部均值的差的平方做高斯模糊处理,具体公式为:
σ(i,j)=k=−K∑Kl=−L∑Lwk,l[I(i+k,j+l)−μ(i,j)]2
二、Patch Selection 筛选图像块
由于人类似乎更重视他们对清晰图像区域的图像质量判断。我们使用一个简单的设备从一组自然补丁中优先选择那些信息最丰富且不太可能受到限制失真的补丁。因此我们的筛选标准是:边缘更锐利的,包含信息内容更丰富的。
在归一化后,筛选前,作者将图像分成大小为PxP的若干个图像块(P=96),索引为b = 1,2,3,...,B,再对每个图像块求平均方差:
δ(b)=∑(i,j)∈pathb∑σ(i,j)
这里的δ代表局部图像的锐利程度。
在做筛选的时候,作者将所有的图像块的最大锐利程度的p倍设置为阈值,其中p∈[0.6,0.9],然后将大于阈值的图像块保留,小于阈值的图像全部丢弃。
三、Characterizing Image Patches 求图像块特征
该部分用到GGD(广义高斯分布)和AGGD(非对称广义高斯分布)求图像块特征,首先利用GGD求取图像的两个特征:
f(x,α,β)Γ(a)=2βΓ(α1)αexp[−(β∣x∣)α]=∫0∞ta−1e−tdta>0
并且使用了快速匹配算法得到了参数ɑ和β。
四、Multivariate Gaussian Model 多元高斯模型
已知有拟合高斯模型(MVG):
fX(x1,…,xk)=(2π)2k∣∑∣211×exp[−21(x−ν)TΣ−1(x−ν)]
输入每张清晰图像的特征参数后得到上式,对其做最大似然估计后将得到该模型的均值向量ν和协方差矩阵Σ。
五、NIQE Index 最终得分
D(ν1,ν2,Σ1,Σ2)=(ν1−ν2)T(2Σ1+Σ2)−1(ν1−ν2)
由上式即可得出最终得分,ν1、Σ1是一组清晰图像得到的均值向量和协方差矩阵,而ν2、Σ2是输入的低质量图像得到的均值向量和协方差矩阵。
NIMA
全称:Neural Image Assessment,中文:图像质量评估
NIMA算法是对任意图像都生成评分直方图,即对图像进行1~10分的打分,并直接比较同一主题的图像, 这种设计跟人的评分系统产生的直方图在形式上吻合,且评估效果更接近人类评估的结果。而且这篇论文侧重的是从美学角度进行评分。作者是基于CNN进行训练的,就是将CNN的最后一层替换为具有10个神经元的全连接层,然后进行softmax激活。
该指标算法流程如下:在模型训练的时候,将输入图像缩放为256×256,然后随机提取大小为224×224的裁剪块。训练的目标是预测给定图像的评级分布。这就是预测结果的直方图和真实直方图的比较。
