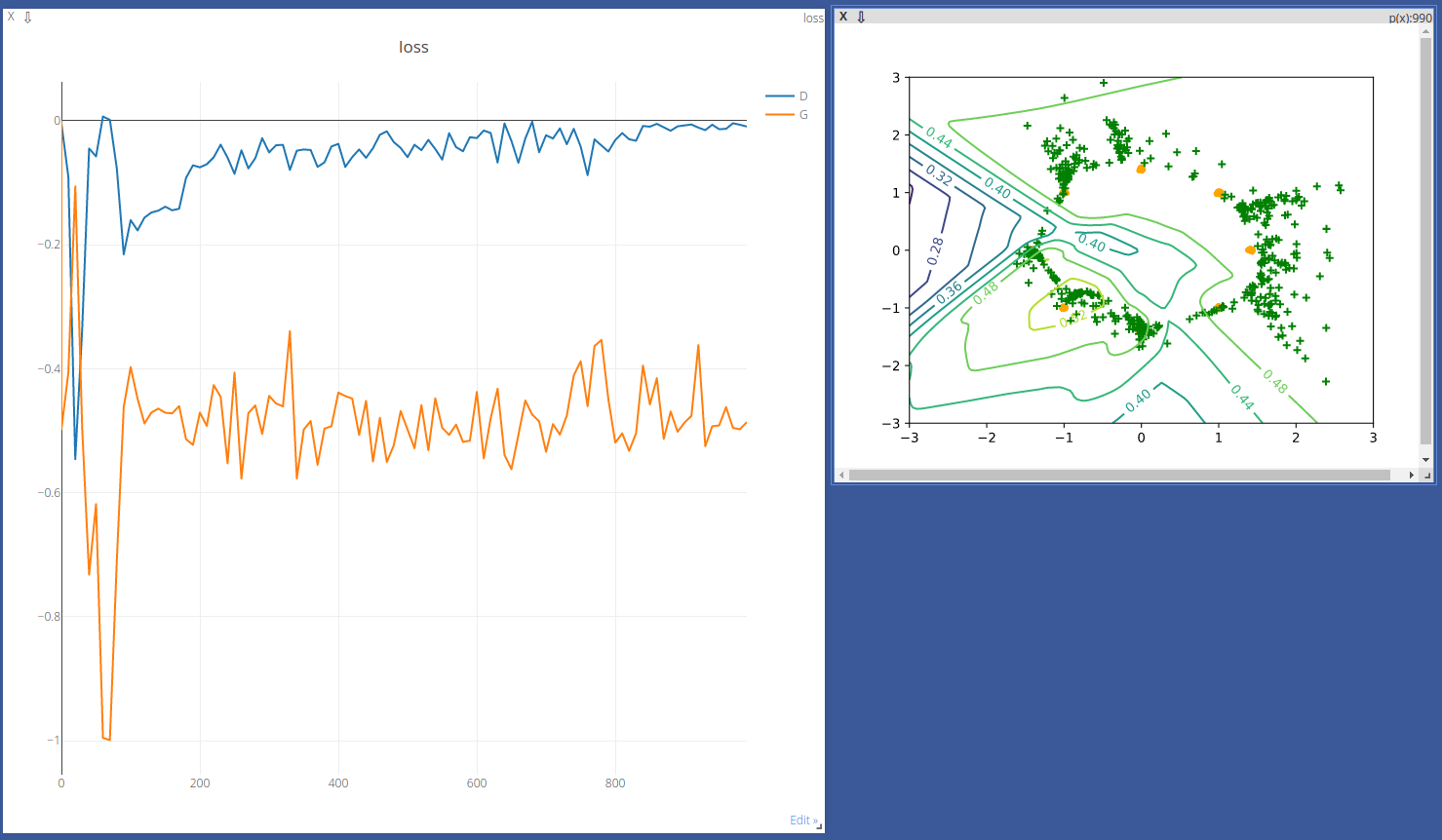
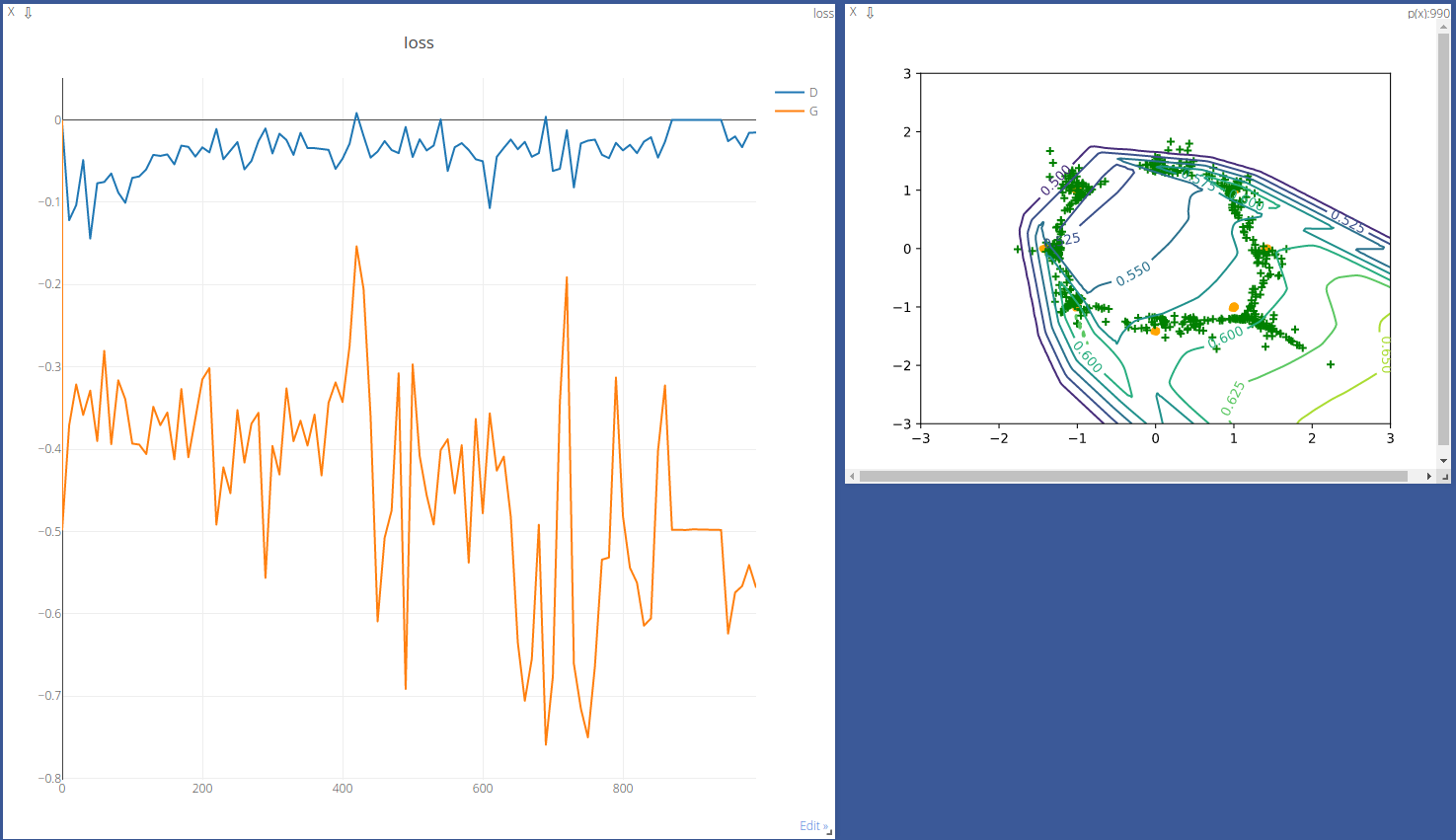
尽管表现差了些,但也比之前的 Standard GAN 要强多了。虽然这里出现了训练不稳定的情况,但还不至于直接导致梯度消失的问题。
Result 1 Result 2 Result 3 从最终结果来看,成绩还没那么糟糕,较多数的点也聚集在黄点的区域附近了。
通俗的解释就是,判别器训练的太好,以至于生成器训练不动!
我们先来看一下 Standard GAN 的损失函数:
L ( G , D ) = 2 D J S ( P r ∣ ∣ P g ) − 2 l o g 2 L(G,D)=2D_{JS}(P_r||P_g)-2log2 L ( G , D ) = 2 D J S ( P r ∣∣ P g ) − 2 l o g 2
为避免你遗忘,再复习一下这两个定义:
D K L ( p ∣ ∣ q ) = ∫ x p ( x ) l o g p ( x ) q ( x ) d x D_{KL}(p||q)=\int_x p(x)log\frac{p(x)}{q(x)}dx D K L ( p ∣∣ q ) = ∫ x p ( x ) l o g q ( x ) p ( x ) d x
D J S = 1 2 D K L ( p ∣ ∣ p + q 2 ) + 1 2 D K L ( q ∣ ∣ p + q 2 ) D_{JS}= \frac{1}{2}D_{KL}(p||\frac{p+q}{2})+\frac{1}{2}D_{KL}(q||\frac{p+q}{2}) D J S = 2 1 D K L ( p ∣∣ 2 p + q ) + 2 1 D K L ( q ∣∣ 2 p + q )
根据前一篇的推导,我们可以看到,如果我们能缩小这个 JS 散度的话,就可以把真实分布和生成分布拉近了,而这正是我们希望看到的,生成器生成的东西会更接近真实。
然而现实总是残酷的,问题就出现在这个JS散度上。 我们对它的希望只能在两个分布有所重叠且重叠部分不可忽略的情况下才能成立。反过来说就是,如果两个分布没有重叠或者有可忽略的重叠,JS散度的结果只能是一个常数( lg 2 \lg2 lg 2
我们试着探究一下,对于任意一个连续随机变量x x x
P 1 ( x ) = 0 ∧ P 2 ( x ) = 0 ; P 1 ( x ) ≠ 0 ∧ P 2 ( x ) ≠ 0 ; P 1 ( x ) ≠ 0 ∧ P 2 ( x ) = 0 ; P 1 ( x ) = 0 ∧ P 2 ( x ) ≠ 0 ; P_1(x)=0\wedge P_2(x)=0\text{;}P_1(x)\not=0\wedge P_2(x)\not=0\text{;} \newline P_1(x)\not=0\wedge P_2(x)=0\text{;}P_1(x)=0\wedge P_2(x)\not=0\text{;} P 1 ( x ) = 0 ∧ P 2 ( x ) = 0 ; P 1 ( x ) = 0 ∧ P 2 ( x ) = 0 ; P 1 ( x ) = 0 ∧ P 2 ( x ) = 0 ; P 1 ( x ) = 0 ∧ P 2 ( x ) = 0 ;
对于第一种情况是对JS散度无贡献的;而第二种情况又因为重叠部分可忽略以至于贡献过小,也可看作无贡献;而对于后两种情况,计算结果皆为lg 2 \lg2 lg 2
而真实分布和生成分布不重叠或者重叠部分可忽略的情况出现的可能性有多大?可以说非常大。而严格来说,则是当P r P_r P r P g P_g P g 支撑集 是高维空间中的低维流形 时P r P_r P r P g P_g P g 测度 为0的概率为1。
提示
支撑集 : 指的是函数的非零部分子集。一个概率分布的支撑集就是所有概率密度非零部分的集合。可以和函数的定义域或者命题的论域等做类比理解。流形 : 是高维空间中曲线、曲面概念的拓广,比如在三维空间中任一曲面都是二维流形,任一曲线是一维流形。测度 : 是高维空间中长度、面积、体积概念的推广,在这里可以大致理解为超体积。
现在,我们再想,一般生成器都是从低维空间中随机生成某一编码向量,再通过神经网络生成高维数据,然而尽管最后数据是高维的,可实质上的维度还是和编码向量维度相同或者比编码向量维度还小(考虑到神经网络带来的映射降维)——因为向量的所有变化都只能分布在低维空间中,而所有的变化又与高维数据形成映射,也就是说,高维空间中的事件空间仅含有低维空间内的所有变化,而不包含高维空间的其余部分。「这就是这位博主说的“撑不满”整个高维空间的意思。」
正是有上面的“撑不满”的问题,真实分布和生成分布就很难有重叠部分,首先要明白,我们寻找的重叠部分实际上是和真实分布、生成分布同维的,那么在整个高维空间中,两个分布即使能相交,得到的重叠部分只能是低维流形,这对于我们要找到的重叠部分而言差的很远,测度显然为 0(可能没有测度,也可能测度过小而可忽略)。
综上所述,在(近似)最优判别器中,最小化生成器L ( G , D ) L(G,D) L ( G , D ) P r P_r P r P g P_g P g P r P_r P r P g P_g P g lg 2 \lg2 lg 2
而我们再宏观把握这个问题:
1.由于P r P_r P r P g P_g P g
2.以神经网络为主体的判别器可无限拟合上面提到的曲面,从而能够出现这样一个最优判别器,对几乎整个真实分布给出概率为1,而对几乎整个生成分布给出概率为 0,而只有那些可忽略的测度为 0 的部分,最优判别器才不能很好地分类。
3.判别器对真实分布和生成分布的概率是常数,这造成生成器损失函数的梯度变成0。
这下就清楚原始 GAN 的问题所在了:如果判别器训练得太好,生成器的梯度就消失,Loss 函数无法下降;如果判别器训练得不好,生成器梯度不准,会生成许多无用的样本。只有将判别器训练得恰到好处才能表现良好,然而这一点非常难做到,像博主所说,“在同一轮训练的前后不同阶段这个火候都可能不一样”,因此原始GAN非常难训练。
后来 Ian Goodfellow 提出了一种改进方式,将生成器的 Loss 改成E x ∼ [ − log D ( x ) ] \mathbb{E}_{x\sim }[-\log D(x)] E x ∼ [ − log D ( x )]
K L ( P g ∣ ∣ P r ) = E x ∼ P g [ log P g ( x ) P r ( x ) ] = E x ∼ P g [ log P g ( x ) P r ( x ) + P g ( x ) P r ( x ) P r ( x ) + ( x ) ] = E x ∼ P g [ log 1 − D ( x ) D ( x ) ] = E x ∼ P g log [ 1 − D ( x ) ] − E x ∼ P g log D ( x ) \begin{align*} KL(P_g||P_r) &=\mathbb{E}_{x \sim P_g}[\log \cfrac{P_g(x)}{P_r(x)}] \\ &=\mathbb{E}_{x \sim P_g}[\log \frac{\cfrac{P_g(x)}{P_r(x)+P_g(x)}}{\cfrac{P_r(x)}{P_r(x)+(x)}}] \\ &=\mathbb{E}_{x \sim P_g}[\log \cfrac{1-D(x)}{D(x)}] \\ &=\mathbb{E}_{x \sim P_g}\log[1-D(x)]-\mathbb{E}_{x \sim P_g}\log D(x) \end{align*} K L ( P g ∣∣ P r ) = E x ∼ P g [ log P r ( x ) P g ( x ) ] = E x ∼ P g [ log P r ( x ) + ( x ) P r ( x ) P r ( x ) + P g ( x ) P g ( x ) ] = E x ∼ P g [ log D ( x ) 1 − D ( x ) ] = E x ∼ P g log [ 1 − D ( x )] − E x ∼ P g log D ( x )
E x ∼ P g [ − log D ( x ) ] = K L ( P g ∣ ∣ P r ) − E x ∼ P g log [ 1 − D ( x ) ] = K L ( P g ∣ ∣ P r ) − 2 J S ( P r ∣ ∣ P g ) + 2 log 2 + E x ∼ P r log D ( x ) \begin{align*} \mathbb{E}_{x\sim P_g}[-\log D(x)]&=KL(P_g||P_r)-\mathbb{E}_{x \sim P_g}\log[1-D(x)]\\ &=KL(P_g||P_r)-2JS(P_r||P_g)+2\log2+\mathbb{E}_{x \sim P_r}\log D(x) \end{align*} E x ∼ P g [ − log D ( x )] = K L ( P g ∣∣ P r ) − E x ∼ P g log [ 1 − D ( x )] = K L ( P g ∣∣ P r ) − 2 J S ( P r ∣∣ P g ) + 2 log 2 + E x ∼ P r log D ( x )
很容易看出来最后两项不依赖生成器,因而最小化该公式就等价于最小化K L ( P g ∣ ∣ P r ) − 2 J S ( P r ∣ ∣ P g ) KL(P_g||P_r)-2JS(P_r||P_g) K L ( P g ∣∣ P r ) − 2 J S ( P r ∣∣ P g )
另外,前面的 KL 散度项也存在问题,因为 KL 散度本身不是对称的衡量,K L ( P g ∣ ∣ P r ) KL(P_g||P_r) K L ( P g ∣∣ P r ) K L ( P r ∣ ∣ P g ) KL(P_r||P_g) K L ( P r ∣∣ P g ) K L ( P g ∣ ∣ P r ) KL(P_g||P_r) K L ( P g ∣∣ P r )
当P g ( x ) → 0 , P r ( x ) → 1 P_g(x)\to 0,P_r(x)\to 1 P g ( x ) → 0 , P r ( x ) → 1 P g ( x ) log P g ( x ) P r ( x ) → 0 P_g(x)\log\frac{P_g(x)}{P_r(x)}\to0 P g ( x ) log P r ( x ) P g ( x ) → 0 K L ( P g ∣ ∣ P r ) KL(P_g||P_r) K L ( P g ∣∣ P r )
当P g ( x ) → 1 , P r ( x ) → 0 P_g(x)\to 1,P_r(x)\to 0 P g ( x ) → 1 , P r ( x ) → 0 P g ( x ) log P g ( x ) P r ( x ) → + ∞ P_g(x)\log\frac{P_g(x)}{P_r(x)}\to +\infty P g ( x ) log P r ( x ) P g ( x ) → + ∞ K L ( P g ∣ ∣ P r ) KL(P_g||P_r) K L ( P g ∣∣ P r )
这代表了惩罚失衡。对于第一种情况,生成器没能生成真实的样本,惩罚却微小,而对于第二种情况,生成器生成了不真实的样本,惩罚却巨大。这样会导致生成器宁可生成重复但不会错的样本,也不会去生成多样的样本,而这就是常见的Collapse Mode 。
WGAN前作针对生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠的问题提出了一种解决方案:向生成样本和真实样本添加噪声。这样就让原本的两个低维流形强行弥散到整个高维空间,从而使两者产生不可忽略的重叠。
显然一旦存在重叠,JS 散度就可以发挥作用,当两个分布靠近的时候,JS 散度也会减小,而不再是恒为常数了,这样就可以解决生成器梯度消失问题了。训练过程中还可以对添加的噪声进行退火,缓慢减小其方差,直到最后两个低维流体已经有不可忽略的重叠的时候把噪声完全拿掉,JS 也能正常发挥作用,继续拉近两个低维流形,直到他们接近完全重合为止。
采取这样的方案后,对原来的损失函数
E x ∼ P r ( x ) [ log D ( x ) ] + E x ∼ P g ( x ) [ log ( 1 − D ( x ) ) ] = 2 J S ( P r ∣ ∣ P g ) − 2 log 2 \mathbb{E}_{x\sim P_r(x)}[\log D(x)]+\mathbb{E}_{x\sim P_g(x)}[\log(1-D(x))]=2JS(P_r||P_g)-2\log2 E x ∼ P r ( x ) [ log D ( x )] + E x ∼ P g ( x ) [ log ( 1 − D ( x ))] = 2 J S ( P r ∣∣ P g ) − 2 log 2
取反可得判别器最小 loss 为
min L D ( P r + ϵ , P g + ϵ ) = − E x ∼ P r + ϵ [ log D ( x ) ] − E x ∼ P g + ϵ [ log ( 1 − D ( x ) ) ] \min L_D(P_{r+\epsilon},P_{g+\epsilon})=-\mathbb{E}_{x\sim P_{r+\epsilon}}[\log D(x)]-\mathbb{E}_{x\sim P_{g+\epsilon}}[\log(1-D(x))] min L D ( P r + ϵ , P g + ϵ ) = − E x ∼ P r + ϵ [ log D ( x )] − E x ∼ P g + ϵ [ log ( 1 − D ( x ))]
在这里就要引入一个新的概念:Wasserstein 距离(又称 Earth-Mover 距离、 EM 距离),定义如下:
W ( P r , P g ) = i n f γ ∼ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] W(P_r,P_g)=\underset{\gamma\sim\Pi(P_r,P_g)}{inf}\mathbb{E}_{(x,y)\sim\gamma}[||x-y||] W ( P r , P g ) = γ ∼ Π ( P r , P g ) in f E ( x , y ) ∼ γ [ ∣∣ x − y ∣∣ ]
其中Π ( P r , ) \Pi(P_r,) Π ( P r , ) P r P_r P r P g P_g P g P r P_r P r P g P_g P g γ \gamma γ Π ( P r , ) \Pi(P_r,) Π ( P r , ) ( x , y ) ∼ γ (x, y)\sim\gamma ( x , y ) ∼ γ x x x y y y ∣ ∣ x − y ∣ ∣ ||x-y|| ∣∣ x − y ∣∣ γ \gamma γ E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] E_{(x,y)\sim\gamma}[||x-y||] E ( x , y ) ∼ γ [ ∣∣ x − y ∣∣ ] i n f γ ∼ Π ( P r , P g ) E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] \underset{\gamma\sim\Pi(P_r,P_g)}{inf}\mathbb{E}_{(x,y)\sim\gamma}[||x-y||] γ ∼ Π ( P r , P g ) in f E ( x , y ) ∼ γ [ ∣∣ x − y ∣∣ ]
这里直接引用博主的解释,博主的讲解还是比较准确的:
直观上可以把E ( x , y ) ∼ γ [ ∣ ∣ x − y ∣ ∣ ] \mathbb{E}_{(x,y)\sim\gamma}[||x - y||] E ( x , y ) ∼ γ [ ∣∣ x − y ∣∣ ] γ \gamma γ P r P_r P r P g P_g P g W ( P r , P g ) W(P_r, P_g) W ( P r , P g )
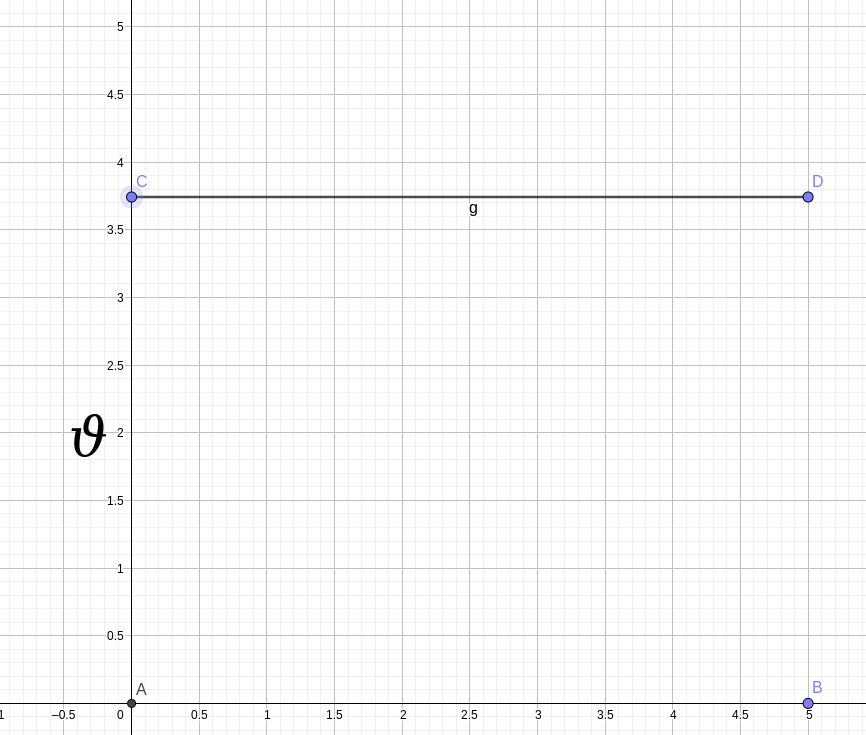
Wasserstein 距离相比 KL 散度和 JS 散度的优势在于,即使真实分布和生成分布没有任何重叠,Wasserstein 距离仍然能够反映它们的远近程度。下面我们来做一个平行比较:
Distributions 其中P 1 P_1 P 1 P 2 P_2 P 2
K L ( P 1 ∣ ∣ P 2 ) = { + ∞ i f ϑ ≠ 0 0 i f ϑ = 0 KL(P_1||P_2)= \begin{cases} +\infty \qquad if \,\, \vartheta \neq 0\\ 0 \qquad\quad\,\, if \,\, \vartheta = 0 \end{cases} K L ( P 1 ∣∣ P 2 ) = { + ∞ i f ϑ = 0 0 i f ϑ = 0
J S ( P 1 ∣ ∣ P 2 ) = { + ∞ i f ϑ ≠ 0 0 i f ϑ = 0 JS(P_1||P_2)= \begin{cases} +\infty \qquad if \,\, \vartheta \neq 0 \\ 0 \qquad\quad\,\, if \,\, \vartheta = 0 \end{cases} J S ( P 1 ∣∣ P 2 ) = { + ∞ i f ϑ = 0 0 i f ϑ = 0
W ( P 1 , P 2 ) = ∣ ϑ ∣ W(P_1,P_2)=|\vartheta| W ( P 1 , P 2 ) = ∣ ϑ ∣
从中我们不难发现,KL 散度、JS 散度在ϑ = 0 \vartheta=0 ϑ = 0 ϑ = 0 \vartheta=0 ϑ = 0
那么我们理解 Wasserstein 距离之后,该如何构建 GAN 网络模型呢?将它定义为生成器的 Loss 函数,产生有意义的梯度,从而将生成分布拉向真实分布吗?然而我们回看这个定义,会发现如果要求解i n f γ ∼ Π ( P r , ) \underset{\gamma\sim\Pi(P_r,)}{inf} γ ∼ Π ( P r , ) in f
W ( P r , ) = 1 K sup ∣ ∣ f ∣ ∣ L ≤ K E x ∼ P r [ f ( x ) ] − E x ∼ P g [ f ( x ) ] W(P_r, ) = \frac{1}{K} \sup_{||f||_L \leq K} \mathbb{E}_{x \sim P_r} [f(x)] - \mathbb{E}_{x \sim P_g} [f(x)] W ( P r , ) = K 1 ∣∣ f ∣ ∣ L ≤ K sup E x ∼ P r [ f ( x )] − E x ∼ P g [ f ( x )]
具体过程请去查阅相关论文 的附录C。
在进一步解释这个公式之前,我们需要知道利普希茨连续(Lipschitz Continuity)的概念。
利普希茨连续
对于在实数集的子集的函数f : D ⊆ R → R {\displaystyle f\colon D\subseteq \mathbb {R} \to \mathbb {R} } f : D ⊆ R → R K {\displaystyle K} K ∣ f ( a ) − f ( b ) ∣ ≤ K ∣ a − b ∣ ∀ a , b ∈ D |f(a)-f(b)|\leq K|a-b|\quad \forall a,b\in D ∣ f ( a ) − f ( b ) ∣ ≤ K ∣ a − b ∣ ∀ a , b ∈ D f {\displaystyle f} f f f f K {\displaystyle K} K f {\displaystyle f} f
若K < 1 K<1 K < 1 f f f
利普希茨条件也可对任意度量空间的函数定义:
给定两个度量空间( M , d M ) , ( N , d N ) , U ⊆ M (M,d_{M}),(N,d_{N}),U\subseteq M ( M , d M ) , ( N , d N ) , U ⊆ M f : U → N f:U\to N f : U → N K K K d N ( f ( a ) , f ( b ) ) ≤ K d M ( a , b ) ∀ a , b ∈ U d_{N}(f(a),f(b))\leq Kd_{M}(a,b)\quad \forall a,b\in U d N ( f ( a ) , f ( b )) ≤ K d M ( a , b ) ∀ a , b ∈ U
若存在K ≥ 1 K\geq 1 K ≥ 1 1 K d M ( a , b ) ≤ d N ( f ( a ) , f ( b ) ) ≤ K d M ( a , b ) ∀ a , b ∈ U {\frac{1}{K}}d_{M}(a,b)\leq d_{N}(f(a),f(b))\leq Kd_{M}(a,b)\quad \forall a,b\in U K 1 d M ( a , b ) ≤ d N ( f ( a ) , f ( b )) ≤ K d M ( a , b ) ∀ a , b ∈ U f f f 双利普希茨 (bi-Lipschitz)。
满足 Lipschitz 连续条件的函数f f f
连续 的定义:
∀ x , ε ( ε > 0 ) , ∃ δ > 0 , 使得当 ∣ x − x 0 ∣ < δ 时,都有 ∣ f ( x ) − f ( x 0 ) ∣ < ε . \forall x,\varepsilon (\varepsilon > 0), \exist \delta>0, \text{使得当} |x-x_0|<\delta\text{时,都有}|f(x)-f(x_0)| < \varepsilon. ∀ x , ε ( ε > 0 ) , ∃ δ > 0 , 使得当 ∣ x − x 0 ∣ < δ 时,都有 ∣ f ( x ) − f ( x 0 ) ∣ < ε .
一致连续 的定义:
∀ ε > 0 , ∃ δ > 0 , 使得 ∀ x , x 0 , 当 ∣ x − x 0 ∣ < δ 时,都有 ∣ f ( x ) − f ( x 0 ) ∣ < ε \forall \varepsilon > 0, \exist \delta > 0, \text{使得} \forall x, x_0, \text{当}|x-x_0|<\delta\text{时,都有}|f(x)-f(x_0)|<\varepsilon ∀ ε > 0 , ∃ δ > 0 , 使得 ∀ x , x 0 , 当 ∣ x − x 0 ∣ < δ 时,都有 ∣ f ( x ) − f ( x 0 ) ∣ < ε
则有
已知 f ( x ) 满足利普希茨连续条件 : \text{已知}f(x)\text{满足利普希茨连续条件}: 已知 f ( x ) 满足利普希茨连续条件 :
∵ ∀ x , x 0 ∈ D f , ∃ K 使得 ∣ f ( x ) − f ( x 0 ) ∣ ≤ K ∣ x − x 0 ∣ 又 ∵ ∃ δ > 0 使得 ∣ x − x 0 ∣ < δ ⇒ ∣ f ( x ) − f ( x 0 ) ∣ < K δ 不妨设 ε = K δ , 则有 ∣ f ( x ) − f ( x 0 ) ∣ < ε . ∴ 函数 f 在 D f 上一致连续,显然 f ( x ) 连续 . \because\forall x,x_0\in D_f, \exists K\text{使得}|f(x)-f(x_0)|\leq K|x-x_0| \\ \text{又}\because \exist \delta > 0\text{使得} |x-x_0|<\delta \Rightarrow |f(x)-f(x_0)| < K\delta \\ \text{不妨设} \varepsilon = K\delta, \text{则有} |f(x)-f(x_0)| < \varepsilon. \\ \therefore \text{函数}f\text{在}D_f\text{上一致连续,显然}f(x)\text{连续}. \\ ∵ ∀ x , x 0 ∈ D f , ∃ K 使得 ∣ f ( x ) − f ( x 0 ) ∣ ≤ K ∣ x − x 0 ∣ 又 ∵ ∃ δ > 0 使得 ∣ x − x 0 ∣ < δ ⇒ ∣ f ( x ) − f ( x 0 ) ∣ < Kδ 不妨设 ε = Kδ , 则有 ∣ f ( x ) − f ( x 0 ) ∣ < ε . ∴ 函数 f 在 D f 上一致连续,显然 f ( x ) 连续 .
Q . E . D . \mathcal{Q.E.D.} Q . E . D .
综合证明来看,Lipschitz 连续条件是一个比一致连续更强的光滑性条件,所以有下面博主的表述:
它其实就是在一个连续函数f f f K ≥ 0 K\geq 0 K ≥ 0 x 1 x_1 x 1 x 2 x_2 x 2 ∣ f ( x 1 ) − f ( x 2 ) ∣ ≤ K ∣ x 1 − x 2 ∣ |f(x_1) - f(x_2)| \leq K |x_1 - x_2| ∣ f ( x 1 ) − f ( x 2 ) ∣ ≤ K ∣ x 1 − x 2 ∣
我们再看下面的这个公式
W ( P r , P g ) = 1 K sup ∣ ∣ f ∣ ∣ L ≤ K E x ∼ P r [ f ( x ) ] − E x ∼ P g [ f ( x ) ] ( A ) W(P_r, P_g) = \frac{1}{K} \sup_{||f||_L \leq K} \mathbb{E}_{x \sim P_r} [f(x)] - \mathbb{E}_{x \sim P_g} [f(x)] \quad\quad(A) W ( P r , P g ) = K 1 ∣∣ f ∣ ∣ L ≤ K sup E x ∼ P r [ f ( x )] − E x ∼ P g [ f ( x )] ( A )
在要求∣ ∣ f ∣ ∣ L ≤ K ||f||_L \leq K ∣∣ f ∣ ∣ L ≤ K f f f E x ∼ P r [ f ( x ) ] − E x ∼ P g [ f ( x ) ] \mathbb{E}_{x \sim P_r} [f(x)] - \mathbb{E}_{x \sim P_g} [f(x)] E x ∼ P r [ f ( x )] − E x ∼ P g [ f ( x )]
如果存在某函数f ω f_\omega f ω ω \omega ω
W ( P r , P g ) ≈ 1 K max ω ∣ f ω ∣ L ≤ K E x ∼ P r [ f ω ( x ) ] − E x ∼ P g [ f ω ( x ) ] ( B ) W(P_r, P_g) \approx \frac{1}{K} \max_{\omega|f_\omega|_L \leq K} \mathbb{E}_{x \sim P_r} [f_\omega(x)] - \mathbb{E}_{x \sim P_g} [f_\omega(x)] \quad \quad (B) W ( P r , P g ) ≈ K 1 ω ∣ f ω ∣ L ≤ K max E x ∼ P r [ f ω ( x )] − E x ∼ P g [ f ω ( x )] ( B )
这样定义出来的函数虽然不能囊括所有可能,至少可以足够接近我们希望求得的原式。那么如何得到上面提到的函数?「由ω \omega ω
最后还不能忘记公式的前提条件∣ ∣ f ∣ ∣ L ≤ K ||f||_L \leq K ∣∣ f ∣ ∣ L ≤ K K K K ω i \omega_i ω i [ − c , c ] [-c,c] [ − c , c ] x x x
现在我们构造一下判别器的损失函数。含参数ω \omega ω f ω f_\omega f ω ω \omega ω
L = E x ∼ P r [ f w ( x ) ] − E x ∼ P g [ f w ( x ) ] L = \mathbb{E}_{x \sim P_r} [f_w(x)] - \mathbb{E}_{x \sim P_g} [f_w(x)] L = E x ∼ P r [ f w ( x )] − E x ∼ P g [ f w ( x )]
取到最大,此时L L L K K K
注意
Standard GAN 的判别器要做的是真假二分类任务,因此最后一层才会采用 sigmoid 函数处理,而现在WGAN的判别器做的是近似拟合 Wasserstein 距离,是回归问题,因此最后一层不使用非线性结构,要把 sigmoid 函数去掉。
接着要与判别器博弈的生成器需要近似最小化 Wasserstein 距离,也就是最小化L L L L L L E x ∼ P r [ f w ( x ) ] \mathbb{E}_{x \sim P_r} [f_w(x)] E x ∼ P r [ f w ( x )]
最终整个 WGAN 的两个 Loss 函数就构建完成了:
L G = − E x ∼ P g [ f w ( x ) ] L D = E x ∼ P g [ f w ( x ) ] − E x ∼ P r [ f w ( x ) ] \begin{align} &\quad\quad L_G=-\mathbb{E}_{x\sim P_g}[f_w(x)]\\ &\quad\quad L_D=\mathbb{E}_{x\sim P_g} [f_w(x)]- \mathbb{E}_{x \sim P_r} [f_w(x)] \end{align} L G = − E x ∼ P g [ f w ( x )] L D = E x ∼ P g [ f w ( x )] − E x ∼ P r [ f w ( x )]
只消在 Standard GAN 代码的基础上再加上:
def weights_init ( m ): if isinstance (m, nn.Linear): # m.weight.data.normal_(0.0, 0.02) nn.init. kaiming_normal_ (m.weight) m.bias.data. fill_ ( 0 ) 然后在main函数中初始化变量_clip为0.025「你也可以自己设定」,然后在声明的G和D后面插入两行代码:
G. apply (weights_init) D. apply (weights_init) 并在判别器训练的代码块后生成器训练的代码块之前添加如下代码:
for w in D. parameters (): w.data. clamp_ ( - _clip, _clip) 为了出现上面贴的图,我将后面的if epoch %后的数改成10,for epoch in range后括号内的数改成1000。
到此为止代码也就改完了,我们的WGAN也实现了!
完整代码请点这里查看→ \rightarrow → WGAN