
线性表
线性表是具有相同数据据类型的个数据元素的有限序列,其中为表长,当时线性表是一个空表。
表头元素是线性表里的唯一的第一个数据元素,而表尾元素是唯一的最后一个数据元素。
线性表的特点:
- 表中元素的个数有限
- 表中元素具有逻辑上的顺序性,表中元素有其先后次序。
- 表中元素都是数据元素,每个元素都是单个元素。
- 表中元素的数据类型都相同,每个元素占有相同大小的存储空间。
- 表中元素具有抽象性,仅讨论元素间的逻辑关系而不考虑其表示的内容。
考研中可直接使用的线性表的基本操作
- InitList(&L): 初始化表
- Length(L): 求表长
- LocateElem(L, e): 按值查找
- GetElem(L, i): 按位查找
- ListInsert(&L, i, e): 插入元素
- ListDelete(&L, i, e): 删除元素
- PrintList(L): 输出操作
- Empty(L): 判空操作
- DestoryList(&L): 销毁操作
线性表的顺序表示
顺序表是线性表的顺序存储,它是用一组地址连续的存储单元依次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素在物理位置上也相邻(此即顺序表的特点)。
我们称第个元素的为位序。若设为线性表存储的起始位置,为每个数据元素所占用的存储空间的大小,那么对于第个元素的指针地址为为该表的长度。
线性表的顺序存储结构是一种随机存取的存储结构。
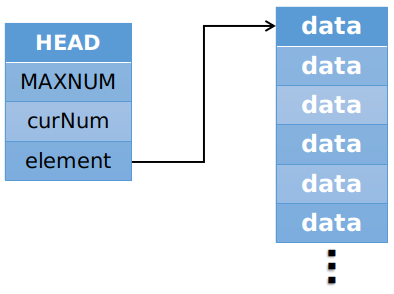
通常顺序表的组成成分如下:
- 头指针结构:包含最大储存空间、当前存有数据量和线性表三个成员。
- 线性表结构:一个连续存储的数组。
如图所示:
结构定义的代码:
typedef int DataType;
typedef struct {
DataType *element;
int MAXNUM, length;
} seqList, *PseqList;
enum { MAXNUM = 50 };
typedef int DataType;
typedef struct {
DataType element[MAXNUM];
int length;
} seqList, *PseqList;
创建
实现思路:创建空的顺序线性表非常容易,只需要知道固定的空间大小即可,同时也可记录该线性表中最大空间和当前存有数据量。
//创建头指针用于建立顺序线性表
PseqList createNullList_seq(int m){
PseqList HEAD = (PseqList)malloc(sizeof(struct seqList));
HEAD->MAXNUM = m;
HEAD->length = 0;
if ( m )
HEAD->element = (DataType*)malloc(sizeof(DataType) * HEAD->MAXNUM);
else
HEAD->element = NULL;
// C++
// HEAD->element = new DataType[HEAD->MAXNUM];
return HEAD;
}
注意:之所以没有直接写成
struct seqList HEAD;是因为使用这样的写法会导致栈空间的浪费,还会存在不可预知的被回收掉的风险。想了解底层原因请点击这里
插入
实现思路:在指定位置插入新的数据,就需要将后面所有的数据向后移动一位来给新的数据腾出空间,移动完毕后就可以将新的数据放入指定位置了。
//判断是否已满,是为了验证能否继续插入的先决条件
int isFullList_seq(PseqList L) {
if (L->length < L->MAXNUM) {
return 0;
} else {
return 1;
}
}
//在指定位置插入数据
int insertP_seq(PseqList L, int p, DataType x) {
if (isFullList_seq(L)) {
printf("list is full");
return 0;
} else if (p > L->length + 1 || p < 0) {
printf("position is illegel");
return 0;
} else {
for (int i = L->length - 1; i >= p; --i) {
L->element[i + 1] = L->element[i];
}
L->element[p] = x;
L->length++;
return 1;
}
}
//在指定位置的前面插入数据
int insertPre_seq(PseqList L, int p, DataType x) {
if (insertP_seq(L, p - 1, x)) {
return 1;
} else {
return 0;
}
}
//在指定位置的后面插入数据
int insertPost_seq(PseqList L, int p, DataType x) {
if (insertP_seq(L, p + 1, x)) {
return 1;
} else {
return 0;
}
}
时间复杂度:
最好情况:在表尾插入,元素后移语句将不执行,此时时间复杂度为。
最坏情况:在表头插入,元素后移语句将执行次,此时时间复杂度为。
平均情况:
假设是在第个位置上插入一个结点的概率,则在长度为的线性表中插入一个结点时,所需移动结点的平均次数为
综上所述,该操作的时间复杂度为。
输出
void printList_seq(PseqList L) {
for (int i = 0; i < L->length; ++i) {
printf("%d ", L->element[i]);
}
}
时间复杂度:该函数执行时间与用户输入的数据规模线性相关,因此认为时间复杂度为。
查询
实现思路:由于查询顺序线性表有两种查找方式,一种是按索引查找值,另一种则是按值查找索引。
按索引查找值:只需要确定偏移量,直接访问线性表起点偏移后对应的空间即可。
按值查找索引:关于搜索算法有许多种,这里仅提最简单的顺序查找。顺序查找的思路是:从线性表起点开始,一位一位地向后探查,找到第一个与查找值相同时立即返回其对应的索引。
DataType locatePos_seq(PseqList L, int pos) {
if (pos >= L->length || pos < 0) {
return L->element[0];
} else {
return L->element[pos];
}
}
int locate_seq(PseqList L, int x) {
for (int i = 0; i < L->length; ++i) {
if (L->element[i] == x)
return i;
}
return -1;
}
时间复杂度:
由于顺序表具有随机访存的特点,所以时间复杂度为。
最好情况:查找的元素在表头,仅需比较一次,时间复杂度为。
最坏情况:查找的元素在表尾,需要比较次,时间复杂度为。
一般情况:假设是查找的元素在第个位置上的概率(),则在长度为的线性表中查找指定值的元素所需比较的平均次数为
综上所述,该操作的时间复杂度为。
删除
实现思路:删除元素,即需要从线性表所有数据中抹除掉指定的元素,抹除掉旧数据,新数据自然需要向前一位来占空,那么这一系列操作可以直接简化为:将指定元素以后的所有数据都向前一位,覆盖原来的数据。
如果想删除所有指定值的元素,则只需要将上面删除单个元素的操作重复几次即可。
int deletePos_seq(PseqList L, int pos) {
if (pos >= L->length || pos < 0) {
return -1;
} else {
for (int i = pos; i < L->length - 1; ++i) {
L->element[i] = L->element[i + 1];
}
L->length--;
}
return 1;
}
int delete_seq(PseqList L, int x) {
int num = 0;
for (int i = 0; i < L->length; ++i) {
if (L->element[i] == x) {
deletePos_seq(L, i);
num++;
--i;
}
}
return num;
}
时间复杂度:
最好情况:删除表尾元素,此时无需移动元素,时间复杂度为。
最坏情况:删除表头元素,此时需要移动除表头元素外所有元素,时间复杂度为。
平均情况:
假设是删除第个位置上结点的概率,则在长度为的线性表中删除一个结点时,所需移动结点的平均次数为
综上所述,该操作的时间复杂度为。
最好情况:表中不存在指定指,此时无需做任何操作,仅仅遍历整个表,时间复杂度为。
最坏情况:表中所有元素都是指定值,此时需要执行次删除操作,考虑到对于一次删除操作的平均时间复杂度为,该操作的时间复杂度为。
平均情况:
假设表中有个待删除的元素,则需要执行删除操作的概率为,则表的遍历执行次数为
根据删除单个元素的平均时间复杂度为可知删除值为指定值的所有元素的时间复杂度为。
修改
实现思路:该操作仅在查找指定值操作的基础上多了一步修改的操作,即每找到一个符合条件的值时执行修改数据的操作。
//修改指定值
void replace_seq(PseqList L, int x, int y) {
for (int i = 0; i < L->length; ++i) {
if (L->element[i] == x) {
L->element[i] = y;
}
}
return;
}
时间复杂度:该操作需要比较次,因此时间复杂度为。
顺序表的优缺点
优点:
- 查询速度快,简单、运算方便,更适合小线性表或者固定长度的线性表。
缺点:
- 删除和插入效率低
- 存储空间容易出现上溢
- 容易导致空间浪费。
线性表的链式表示——单链表
定义:单链表是线性表的链式存储,它是指通过一组任意的存储单元来存储线性表中的数据元素,而为了建立数据元素之间的线性关系,对每个链表结点,除存放元素自身的信息外,还需要存放一个指向其后继的指针。
单链表结构如图所示:

结构定义的代码:
typedef struct LNode{
ElemType data;
struct LNode* next;
} LNode, *LinkList;
通常用头指针来标识一个单链表。此外,为了操作方便,一般会在第一个结点前附加一个结点,我们称之为头结点。头结点的数据域可以不设置任何信息,也可以记录表长等信息,指针域指向线性表的第一个元素结点。
引入头结点的优点
- 由于第一个数据结点的位置被存放在头结点的指针域中,因此在链表的第一个位置上的操作和在表上的其他位置上的操作一致,无需特殊处理。
- 无论链表是否为空,其头指针都是指向头结点的非空指针,因此空表和非空表的处理也就得到了统一。
「注」:空表中头结点的指针域为空。
初始化
实现思路:创建一个空链表,即新建一个头指针和一个头结点。
//创建带有头结点的单链表
LinkList createList(){
LinkList HEAD = (LinkList)malloc(sizeof(LNode));
LinkList p = (LinkList)malloc(sizeof(LNode));
p->data = 0;
p->next = NULL;
HEAD->next = p;
if (!HEAD || !p) return NULL;
else return HEAD;
}
插入
实现思路:在头结点和头结点的后一结点之间插入新的结点,考虑到指针和操作系统的特性,有关指针的操作需要注意,应该先由新结点指向头结点的后一结点,然后才能由头结点指向新结点。
「注意」:因为如果先由头结点指向新结点的话,原先头结点指向的原数据域就会完全丢失,丢失到数据流中无法找回。这是因为原数据域的地址我们本来就不知道,现在还没有指针能够指向它,那么想访问这一数据域显然无从下手。另外,这也造成了一个问题:内存泄漏「Memory Leak」,丢失的内存块我们无法访问,自然也就无法释放它,它毫无用处,却还在占用系统资源,只有当主程序运行结束后由操作系统回收才能解决这个问题。
内存泄漏形象的比喻是“操作系统可提供给所有程序使用的内存空间正在被某个程序榨干”,最终结果是程序运行时间越长,占用内存空间越来越多,最终用尽全部内存空间,整个系统崩溃。
void headInsert(LinkList head, ElemType insData){
LinkList tmp = (LinkList)malloc(sizeof(LNode));
tmp->data = insData;
tmp->next = head->next;
head->next = tmp;
}
实现思路:显然要在表尾插入,就需要先遍历到表尾才能在此基础上做插入。
void tailInsert(LinkList head , ElemType insData){
LinkList tmp = (LinkList)malloc(sizeof(LNode));
tmp->data = insData;
tmp->next = NULL;
LinkList pointer = head->next;
while(pointer->next){
pointer=pointer->next;
}
pointer->next = tmp;
}
时间复杂度:因为需要从表头开始一直向后遍历直到表尾,因此需要访问个结点,最后指针接上新的结点,因此认为时间复杂度为。
实现思路:因为要多次使用尾插法,需要使用尾指针作为辅助变量来完成操作,每插入一个结点就更新一次尾指针。
LinkList ListTailInsert(LinkList L){ // 传入的单链表L应为空表
LinkList tail = L->next;
LNode tmp;
while(scanf("%d", data)){
tmp = (LNode)malloc(sizeof(LNode));
tmp->data = data;
tail->next = tmp;
tail = tmp;
}
return L;
}
实现思路:与尾插法创建新表方法类似,但是先遍历原来旧表到尾结点后再插入一组数据。
LinkList ListTailInsert(LinkList L){ // 传入的单链表L应为空表
LinkList tail = L->next;
while(tail->next){
tail=tail->next;
}
LNode tmp;
while(scanf("%d", data)){
tmp = (LNode)malloc(sizeof(LNode));
tmp->data = data;
tail->next = tmp;
tail = tmp;
}
return L;
}
不难发现其实尾插法插入一组数据这种方法实际上就是尾插法创建新表后合并两个表。
实现思路:插入结点操作将新结点插入到单链表的第个结点之后,因此需要先检查插入位置的合法性,然后找到待插入位置的前驱结点,即第个结点,再在其后插入新结点。
p=GetElem(L, i);
s->next = p->next;
p->next = s;
「注」:s->next = p->next;一定要在p->next = s;之前,否则会导致指针p以后的所有结点全部丢失。
前插操作指在某结点前面插入一个新结点,后插操作反之。在单链表插入操作中一般都采用后插操作。
实现思路一:找到第个结点后对其进行后插操作
p=GetElem(L, i-1);
s->next = p->next;
p->next = s;
实现思路二:对第个结点进行后插操作,然后将新结点的数据与该结点的数据进行交换。
ElemType tmp;
p=GetElem(L, i);
s->next = p->next;
p->next = s;
tmp = p->data, p->data = s->data, s->data = tmp;
输出
void printList(LinkList L){
LinkList pointer = L->next->next;
while(pointer){
printf("%d\t", pointer->data);
pointer = pointer->next;
}
}
逆置
实现思路:要将链表中所有结点的顺序逆置,考虑到结点插入方式的特性,选用头插法可以实现。先把表拆成只有一个结点的单链表和一组结点,然后将这组结点用头插法插入空表。
void reverseList_link(LinkList L){
LinkList tmp = NULL;
LinkList saver = L->next->next->next; // 第一个结点的后继结点
LinkList headNode = L->next; // 头结点
LinkList tailNode = L->next->next; // 第一个结点
tailNode->next = NULL;
while(saver){
tmp = saver;
saver = saver->next;
tmp->next = headNode->next;
headNode->next = tmp;
}
}
时间复杂度:由于要针对个数据进行插入操作,因此时间复杂度是。
查询
实现思路:查找指定值对应的索引,就需要从表头开始向后遍历,并开始从0计数,找到指定值时返回计得的数,否则返回未找到的信号「如-1等」。
int locateNode(LinkList L, ElemType data){
LinkList headNode = L->next;
LinkList linkWatcher = headNode->next;
// LinkList linkWatcher = L->next; // 若单链表没有头结点的结构则使用这行
int index = 0;
while(linkWatcher){
if (linkWatcher->data == data)
return index;
linkWatcher = linkWatcher->next;
index++;
}
return -1;
}
实现思路:获取用户输入的索引记为,在有效范围内,从表头开始向后遍历,遍历次后返回指针指向的数据区域的值;若超出范围则返回未找到的信号「如-1等」。
int locateNode(LinkList L, int position){
LinkList headNode = L->next;
LinkList linkWatcher = headNode->next;
// LinkList linkWatcher = L->next; // 若单链表没有头结点的结构则使用这行
if (position < 0) return -1;
for (int i = 0; linkWatcher && i < position; ++i) {
linkWatcher = linkWatcher->next;
}
return linkWatcher->data;
}
删除与销毁
实现思路一:先检查删除位置的合法性,后查找表中第个结点,即被删除的前驱结点,另其指针域指向后继的后继结点,再将第个结点删除。
p = GetElem(L, i-1);
q = p->next; // 待删除的结点
p->next = q->next;
free(q);
实现思路二:先检查删除位置的合法性,后查找表中第个结点,即被删除的结点,将其后继的数据覆盖到该结点的数据上,再删除后继结点。
p = GetElem(L, i);
q = p->next;
p->data = q->data;
p->next = q->next;
free(q);
实现思路:因为链表是分散分布在内存空间中的,不能一次性批量释放,只能顺着链表一节一节地释放。
int destroyList(LinkList L) {
int deletedNum = 0;
LinkList firstNode = L->next;
LinkList tmp = NULL;
while (firstNode) {
tmp = firstNode;
firstNode = firstNode->next;
free(tmp);
deletedNum++;
}
return deletedNum;
}
求表长
实现思路:设置一个计数器变量,从第一个结点开始顺序依次放分表中的每个结点,每访问一个结点,计数器加 1,直到访问到空结点为止。
int queryLength(LinkList L){
int a = 0;
LinkList p = L;
while(p){
a++;
p = p->next;
}
return a;
}
int queryLength(LinkList L){
int a = 0;
LinkList p = L->next;
while(p){
a++;
p = p->next;
}
return a;
}
「注意」:单链表的长度不包括头结点,故带头结点的单链表和不带头结点的单链表求表长度方法略有不同。
单链表的优缺点
优点:
- 插入、删除操作十分简单高效,不需要移动元素。
- 不需要指定固定的初始化空间大小。
- 不需要大量连续存储单元。
缺点:
- 存储空间开销更大。
- 不可随机存取。
线性表的链式表示——双链表
单链表结点中只有一个指向后继的指针,使得单链表只能从头结点依次顺序地向后遍历,在要访问前驱结点时只能从头开始遍历,为了克服这个缺点,我们引入了双链表。
双链表结构分指针域,数据域,指针域三部分,两个指针域分别指向前驱结点和后继结点。
typedef struct DNode{
ElemType data;
struct DNode *prior, *next;
} DNode, *DLinkList;
以下仅讨论插入和删除操作,其他操作与单链表基本一致。
插入
实现思路:一般插入操作都是指后插入操作,因此对结点执行后插入操作时考虑先让新结点的前驱与后继确定下来,然后让结点的后继改变前驱为新结点,最后改变结点的后继为新结点。
s->next = p->next;
s->prior = p;
p->next->prior = s;
p->next = s;
插入四步的顺序要求
插入操作的四步顺序并不唯一,但也有相应的限制,即第一行s->next = p->next;和第三行p->next->prior = s;一定要在第四行p->next = s;之前,否则会导致以下问题:
结点原来的后继结点丢失
原因:
p->next = s;在p->next->prior = s;之前所导致的。新结点的后继会指向自己
原因:
p->next = s;在s->next = p->next;之前所导致的。
删除
实现思路:删除结点(结点的后继结点),即需要将结点的后继改为结点的后继,然后将结点的后继改为结点,最后释放掉结点的空间。
p->next = q->next;
q->next->prior = p;
free(q);
实现思路:删除结点(结点的前驱结点),即需要将结点的前驱改为结点的前驱,将结点前驱结点的后继改为结点,最后释放掉结点的空间。
q->prior = p->prior;
p->prior->next = q;
free(p);
双向链表优缺点
优点:
- 可以找到前驱和后继,向前遍历和向后遍历。
- 在当前结点前面、后面插入操作方便
- 针对前驱、后继以及结点本身的删除操作方便。
缺点:
- 增加删除结点操作复杂。
- 较单链表需要占据更多的指针空间。
- 存储密度较单链表低。
线性表的链式表示——循环链表
循环单链表,即令单链表尾结点的指针指向链表的头结点。
typedef struct CNode{
ElemType data;
struct CNode *next;
} CNode, *CLinkList;
这里仅简单讨论判空、插入与删除操作,其他操作与单链表几乎一致。
判空
因为在循环单链表中头指针始终指向头结点,因此判空条件不是头结点指针是否为空,而是头结点的指针是否等于头指针(或者说是否等于它自己)。
插入、删除
循环单链表的插入、删除操作与单链表几乎一致,但不同的是如果操作在表尾进行,则需要让单链表保持循环的性质。
循环单链表本身是一种环,因此在任何位置上插入和删除的操作都是等价的,无需判断是否为表尾。
循环单链表的特殊形式
有时循环单链表不设置头指针而是设置尾指针,这样设置的好处是在表尾插入操作时无需遍历整表,而且在需要访问表头时仍能够直接访问到头结点。
循环单链表的推广——循环双链表
循环双链表可以由循环单链表定义推出,但与之不同的是在循环双链表中头结点的prior要指向表尾结点。
在循环双链表中,某结点为尾结点时,p->next == L(即尾结点的后继指向头结点);当循环双链表为空表时,其头结点的prior和next都等于,即都指向头结点本身。
线性表的链式表示——静态链表
静态链表是借助数组来描述线性表的链式存储结构,结点也有数据域和指针域,但与之前讨论的链表指针不同的是,这里的指针是指结点的相对地址(在数组中的索引),又称游标。和顺序表一样,静态链表也需要预先分配一块连续的内存空间。
enum { MAX_SIZE = 50 };
typedef struct {
ElemType data;
int next;
} SLinkList[MAX_SIZE];
在静态链表中next == -1是结束的标志。静态链表的插入、删除操作与动态链表相同,只需要修改指针,而不需要移动元素。
静态链表的意义?
虽然静态链表使用起来没有单链表方便,但如果在一些不支持指针的高级语言(如Java、Python、Ruby、C#、Swift、Basic等等)中,这将是一种非常巧妙的设计方法。
顺序表与链表的比较
存取(读写)方式
顺序表可以顺序存取,也可以随即存取;链表只能从表头顺序存取元素
逻辑结构与物理结构
采用顺序存储时,逻辑上相邻的元素对应的物理存储位置也相邻;采用链式存储时,逻辑上相邻的元素对应的物理存储位置不一定相邻,对应的逻辑关系是通过指针链接来表示的。
查找、插入和删除操作
对于按值查找,顺序表无序时,两者的时间复杂度均为。而在顺序表有序时,可采用折半查找,此时时间复杂度为。
对于按索引查找,顺序表支持随机访问,时间复杂度仅为,而链表的平均时间复杂度为。
顺序表的插入、删除操作平均需要移动半个表长的元素;链表的插入、删除操作只需修改相关结点的指针域即可。
由于链表的每个结点都带有指针域,故而存储密度不够大。
空间分配
顺序存储在静态存储分配下,一旦存储空间装满就不能扩充,若再加入新元素,则会出现内存溢出,因此需要预先分配足够大的存储空间。预先分配过大,可能会导致顺序表后部大量闲置;预先分配过小,又会造成溢出。
动态存储分配虽然存储空间可以扩充,但需要移动大量元素,导致操作效率降低,而且若内存中没有更大块的连续存储空间,则会导致分配失败。
链式存储的结点空间只在需要时申请分配,只要内存有空间就可以分配,操作灵活、高效。
实际问题中如何选取存储结构?
基于存储的考虑
难以估计线性表长度或存储规模时,不宜采用顺序表;链表不用事先估计存储规模,但链表的存储密度较低,显然链式存储结构的存储密度是小于的。
基于运算的考虑
在顺序表中按序号访问的时间复杂度为,而链表中按序号访问的时间复杂度为,因此若经常做的运算是按序号访问数据元素,则顺序表优于链表。
在顺序表中进行插入、删除操作时,平均移动表中一半的元素,当数据元素的信息量较大且表较长时,这一点是不应忽视的;在链表中进行插入、删除操作时,虽然也要找插入位置,但操作主要是比较操作,从这角度考虑链表优于顺序表。
基于环境的考虑
顺序表容易实现,任何高级语言都有数组类型;链表的操作是基于指针的,相对来讲前者实现更简单。
通常较稳定的线性表选择顺序存储,动态性较强(即需频繁插入、删除操作)的线性表宜选择链式存储。